Install detectron2
# Properly install detectron2. (Please do not install twice in both ways)
GPU연결 확인
import torch, detectron2
! nvcc --version
TORCH_VERSION = "." .join(torch. __version__ .split( "." )[: 2 ])
CUDA_VERSION = torch. __version__ .split( "+" )[ -1 ]
print ( "torch: " , TORCH_VERSION, "; cuda: " , CUDA_VERSION)
print ( "detectron2:" , detectron2. __version__ )
pre-trained detectron2 model실행
im = cv2.imread( "./input.jpg" )
cv2_imshow(im)
이미지를 다운로드하고 OpenCV를 사용하여 이미지를 읽고 출력
Detectron2를 사용하여 이미지에서 객체 인스턴스 분할 모델을 설정하고 실행
cfg = get_cfg()
# add project-specific config (e.g., TensorMask) here if you're not running a model in detectron2's core library
cfg.merge_from_file(model_zoo.get_config_file( "COCO-InstanceSegmentation/mask_rcnn_R_50_FPN_3x.yaml" ))
cfg.MODEL.ROI_HEADS.SCORE_THRESH_TEST = 0.5 # set threshold for this model
# Find a model from detectron2's model zoo. You can use the https://dl.fbaipublicfiles... url as well
cfg.MODEL.WEIGHTS = model_zoo.get_checkpoint_url( "COCO-InstanceSegmentation/mask_rcnn_R_50_FPN_3x.yaml" )
predictor = DefaultPredictor(cfg)
outputs = predictor(im)
이미지 위에 객체 인스턴스 분할 결과를 시각적으로 그리기 위해 Visualizer 클래스를 사용
# We can use `Visualizer` to draw the predictions on the image.
v = Visualizer(im[:, :, :: -1 ], MetadataCatalog.get(cfg.DATASETS.TRAIN[ 0 ]), scale= 1.2 )
out = v.draw_instance_predictions(outputs[ "instances" ].to( "cpu" ))
cv2_imshow(out.get_image()[:, :, :: -1 ])
객체 인스턴스 분할 모델의 예측 결과가 원래 이미지 위에 시각적으로 표시
Custom Dataset 학습( 전처리 과정 )
1. Dataset 준비
# download, decompress the data
! unzip balloon_dataset.zip > /dev/null
2. 데이터셋을 Detectron2의 COCO 형식에 맞게 변환하고 등록
# if your dataset is in COCO format, this cell can be replaced by the following three lines:
# from detectron2.data.datasets import register_coco_instances
# register_coco_instances("my_dataset_train", {}, "json_annotation_train.json", "path/to/image/dir")
# register_coco_instances("my_dataset_val", {}, "json_annotation_val.json", "path/to/image/dir")
from detectron2.structures import BoxMode
def get_balloon_dicts ( img_dir ):
json_file = os.path.join(img_dir, "via_region_data.json" )
with open (json_file) as f:
imgs_anns = json.load(f)
dataset_dicts = []
for idx, v in enumerate (imgs_anns.values()):
record = {}
filename = os.path.join(img_dir, v[ "filename" ])
height, width = cv2.imread(filename).shape[: 2 ]
record[ "file_name" ] = filename
record[ "image_id" ] = idx
record[ "height" ] = height
record[ "width" ] = width
annos = v[ "regions" ]
objs = []
for _, anno in annos.items():
assert not anno[ "region_attributes" ]
anno = anno[ "shape_attributes" ]
px = anno[ "all_points_x" ]
py = anno[ "all_points_y" ]
poly = [(x + 0.5 , y + 0.5 ) for x, y in zip (px, py)]
poly = [p for x in poly for p in x]
obj = {
"bbox" : [np. min (px), np. min (py), np. max (px), np. max (py)],
"bbox_mode" : BoxMode.XYXY_ABS,
"segmentation" : [poly],
"category_id" : 0 ,
}
objs.append(obj)
record[ "annotations" ] = objs
dataset_dicts.append(record)
return dataset_dicts
for d in [ "train" , "val" ]:
DatasetCatalog.register( "balloon_" + d, lambda d=d: get_balloon_dicts( "balloon/" + d))
MetadataCatalog.get( "balloon_" + d). set (thing_classes=[ "balloon" ])
balloon_metadata = MetadataCatalog.get( "balloon_train" )
훈련
from detectron2.engine import DefaultTrainer
from pprint import pprint # pprint 모듈을 임포트합니다
cfg = get_cfg()
cfg.merge_from_file(model_zoo.get_config_file( "COCO-InstanceSegmentation/mask_rcnn_R_50_FPN_3x.yaml" ))
# 학습용 데이터셋을 설정합니다.
cfg.DATASETS.TRAIN = ( "balloon_train" ,)
# 테스트 데이터셋은 사용하지 않습니다.
cfg.DATASETS.TEST = ()
# 데이터 로더 관련 설정을 지정합니다.
cfg.DATALOADER.NUM_WORKERS = 2
# 사전 훈련된 모델 가중치를 설정합니다.
cfg.MODEL.WEIGHTS = model_zoo.get_checkpoint_url( "COCO-InstanceSegmentation/mask_rcnn_R_50_FPN_3x.yaml" )
# 이미지 당 배치 크기와 학습률 관련 설정을 구성합니다.
cfg.SOLVER.IMS_PER_BATCH = 2
cfg.SOLVER.BASE_LR = 0.00025
# 최대 반복 횟수와 학습률 감소 단계를 설정합니다.
cfg.SOLVER.MAX_ITER = 300
cfg.SOLVER.STEPS = []
# ROI 헤드 관련 설정을 구성합니다.
cfg.MODEL.ROI_HEADS.BATCH_SIZE_PER_IMAGE = 128
cfg.MODEL.ROI_HEADS.NUM_CLASSES = 1
# 출력 디렉토리를 생성합니다.
os.makedirs(cfg.OUTPUT_DIR, exist_ok= True )
# DefaultTrainer를 사용하여 모델을 훈련합니다.
trainer = DefaultTrainer(cfg)
trainer.resume_or_load(resume= False )
trainer.train()
# 모델 구조를 보기 좋게 출력합니다.
pprint(trainer.model)
훈련된 모델을 이요한 추론 및 평과
훈련된 모델을 사용하여 추론을 수행하기 위한 설정(configuration)을 설정하고 모델을 로드
from detectron2.utils.visualizer import ColorMode
dataset_dicts = get_balloon_dicts( "balloon/val" )
for d in random.sample(dataset_dicts, 3 ):
im = cv2.imread(d[ "file_name" ])
v = Visualizer(im[:, :, :: -1 ],
metadata=balloon_metadata,
scale= 0.5 ,
instance_mode=ColorMode.IMAGE_BW # remove the colors of unsegmented pixels. This option is only available for segmentation models
)
out = v.draw_instance_predictions(outputs[ "instances" ].to( "cpu" ))
cv2_imshow(out.get_image()[:, :, :: -1 ])
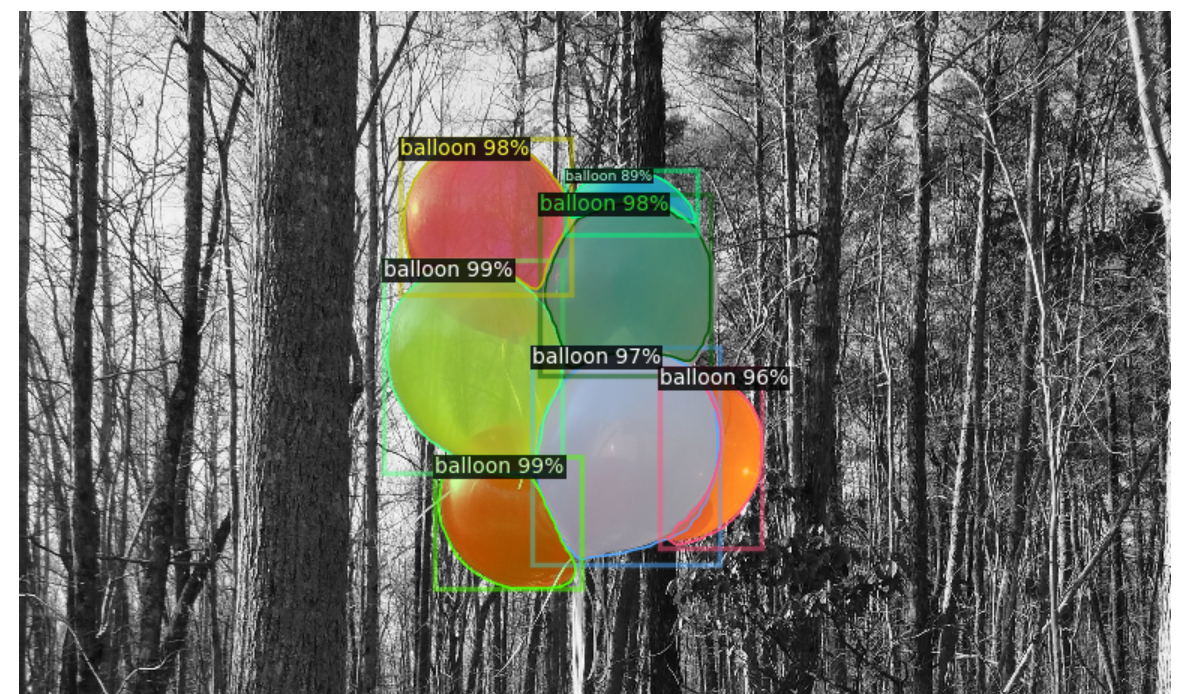
predictor 객체를 사용하여 이미지에서 객체 인스턴스를 예측하고 시각화
Detectron2를 사용하여 훈련한 모델을 검증 데이터셋에 대해 평가
from detectron2.evaluation import COCOEvaluator, inference_on_dataset
from detectron2.data import build_detection_test_loader
evaluator = COCOEvaluator( "balloon_val" , output_dir= "./output" )
val_loader = build_detection_test_loader(cfg, "balloon_val" )
print (inference_on_dataset(predictor.model, val_loader, evaluator))
# another equivalent way to evaluate the model is to use `trainer.test`
평과 결과
"bbox" AP:
> AP: 72.890
> AP50: 85.730
> AP75: 80.976
> APs: 0.000
> APm: 54.905
>APl: 89.305
segm" AP:
> AP: 77.113
> AP50: 83.834
> AP75: 83.834
> APs: 0.000
> APm: 55.910
> APl: 95.538
"bbox" AP의 값이 72.890이고 "segm" AP의 값이 77.113으로 나타나므로, 객체 검출 및 분할에 대한 평균 정밀도(AP)가 약 70 정도로 나타납니다. Not bad!
Detectron2에 내장된 다른 모델을 사용하여 객체 검출 및 분할 작업을 수행
# Inference with a keypoint detection model
cfg = get_cfg() # get a fresh new config
cfg.merge_from_file(model_zoo.get_config_file( "COCO-Keypoints/keypoint_rcnn_R_50_FPN_3x.yaml" ))
cfg.MODEL.ROI_HEADS.SCORE_THRESH_TEST = 0.7 # set threshold for this model
cfg.MODEL.WEIGHTS = model_zoo.get_checkpoint_url( "COCO-Keypoints/keypoint_rcnn_R_50_FPN_3x.yaml" )
predictor = DefaultPredictor(cfg)
outputs = predictor(im)
v = Visualizer(im[:,:,:: -1 ], MetadataCatalog.get(cfg.DATASETS.TRAIN[ 0 ]), scale= 1.2 )
out = v.draw_instance_predictions(outputs[ "instances" ].to( "cpu" ))
cv2_imshow(out.get_image()[:, :, :: -1 ])
Detectron2를 사용하여 키포인트 검출 모델을 사용하여 이미지에서 객체의 키포인트를 예측하고 시각화
패노픽 세그멘테이션 모델을 사용하여 이미지의 패노픽 세그멘테이션을 수행하고 시각화
# Inference with a panoptic segmentation model
cfg = get_cfg()
cfg.merge_from_file(model_zoo.get_config_file( "COCO-PanopticSegmentation/panoptic_fpn_R_101_3x.yaml" ))
cfg.MODEL.WEIGHTS = model_zoo.get_checkpoint_url( "COCO-PanopticSegmentation/panoptic_fpn_R_101_3x.yaml" )
predictor = DefaultPredictor(cfg)
panoptic_seg, segments_info = predictor(im)[ "panoptic_seg" ]
v = Visualizer(im[:, :, :: -1 ], MetadataCatalog.get(cfg.DATASETS.TRAIN[ 0 ]), scale= 1.2 )
out = v.draw_panoptic_seg_predictions(panoptic_seg.to( "cpu" ), segments_info)
cv2_imshow(out.get_image()[:, :, :: -1 ])
패노픽 세그멘테이션: 이미지의 모든 픽셀에 대한 라벨을 할당하는 작업, 객체 검출 및 시맨틱 분할을 결합한 작업
비디오에서 패노픽 세그멘테이션을 실행
1. YouTube에서 호스팅되는 비디오를 표시
YouTubeVideo 객체를 생성하고, 해당 객체를 Jupyter Notebook 환경에서 비디오 플레이어로 표시
# This is the video we're going to process
from IPython.display import YouTubeVideo, display
video = YouTubeVideo( "ll8TgCZ0plk" , width= 500 )
display(video)
2. YouTube 비디오를 다운로드하고, 필요한 부분을 추출하여 video-clip.mp4 파일로 저장
# Install dependencies, download the video, and crop 5 seconds for processing
! pip install yt-dlp
! ffmpeg -i video.mp4 -t 00 : 00 : 06 -c:v copy video-clip.mp4
이 과정에서 두 개의 에러들이 발생하였다
Error 해결:
error 1. youtube-dl 최근 다운로드 누르면 작동안되므로 yt-dlp 로 변경
해결책: ! youtube-dl -> ! yt-dlp
error 2. UTF-8 locale is required. Got ANSI_X3.4-1968
현재 시스템 환경이 UTF-8로 설정되어 있지 않아서 발생
해결책:
import locale
locale.setlocale(locale.LC_ALL, 'en_US.UTF-8' )
3. Detectron2 프레임워크를 사용하여 "video-clip.mp4" 비디오에서 프레임별 추론 데모를 실행
프레임별로 비디오 프레임을 처리하며, 패노픽 세그멘테이션 작업을 수행
# Run frame-by-frame inference demo on this video (takes 3-4 minutes) with the "demo.py" tool we provided in the repo.
%run detectron2/demo/demo.py --config- file detectron2/configs/COCO-PanopticSegmentation/panoptic_fpn_R_101_3x.yaml --video-input video-clip.mp4 --confidence-threshold 0.6 --output video-output.mkv \
--opts MODEL.WEIGHTS detectron2://COCO-PanopticSegmentation/panoptic_fpn_R_101_3x/ 139514519 /model_final_cafdb1.pkl
결과물
'video-output.mkv'
Detectron2 Detectron 2는 Facebook AI Research의 차세대 오픈 소스 객체 감지 시스템입니다. 리포지토리를 사용하면 경계 상자 감지, 인스턴스 및 의미론적 분할, 사람 키포인트 감지와 같은 감지 작업을 위한 다양한 최첨단 모델을 사용하고 훈련할 수 있습니다.
더 빠른 R-CNN FPN 아키텍처
Base RCNN FPN
메타 아키텍처
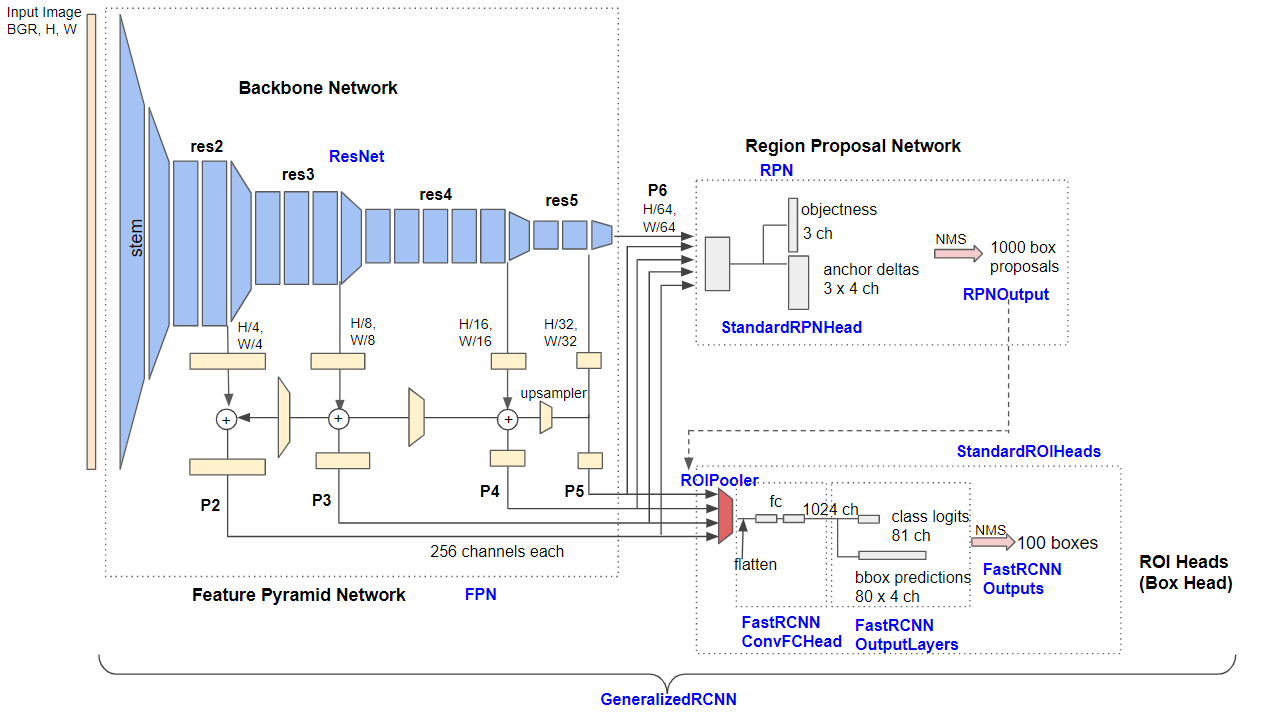
백본 네트워크 (Backbone Network) : 백본 네트워크는 입력 이미지에서 특징 맵을 추출하는 역할을 합니다. 여러 스케일의 특징 맵을 생성하며, 다양한 객체 크기와 위치에 대한 정보를 포함하고 있습니다. 주로 Convolutional Neural Network (CNN) 아키텍처로 구성되며, 객체 검출 작업에서 이미지의 특징을 추출하는 역할을 합니다.Region Proposal Network (RPN) : RPN은 다중 스케일의 특징 맵을 사용하여 객체 영역을 감지하고 제안합니다. 이는 객체 위치를 예측하고 그 신뢰도를 평가하는 역할을 합니다. 기본적으로 1000개의 상자 제안을 생성하며, 이를 후속 단계에서 더 세밀하게 조정하여 정확한 객체 위치를 찾습니다.박스 헤드 (Box Head) : 박스 헤드는 RPN에 의해 생성된 객체 제안을 사용하여 피처 맵을 자르고 변형합니다. 그런 다음, 완전히 연결된 레이어를 통해 제안된 상자의 위치와 해당 객체의 분류 결과를 예측합니다. 최종적으로, 이러한 예측을 NMS(Non-Maximum Suppression)를 사용하여 필터링하고, 최종 객체 검출 결과를 얻습니다.
이러한 구성 요소들을 조합하여 Faster R-CNN은 객체 검출 작업을 수행하며, 다양한 객체 크기 및 배경에서도 높은 정확도를 제공합니다. 이러한 구성 요소는 Detectron2와 같은 프레임워크에서 사용되며, 객체 검출 작업을 수행하는 데 중요한 역할을 합니다.
Base-RCNN-FPN의 세부 아키텍처
Detectron2의 주요 구성 요소
Detectron2는 다음과 같은 주요 구성 요소로 구성됩니다:
백본 네트워크 (Backbone Network): 백본 네트워크는 입력 이미지에서 특징을 추출하는 역할을 합니다. Detectron2에서는 FPN (Feature Pyramid Network) 및 ResNet과 같은 백본 네트워크를 사용할 수 있습니다.지역 제안 네트워크 (Region Proposal Network, RPN): RPN은 객체 제안을 생성하는 네트워크로, 객체가 존재할 가능성이 높은 위치를 제안합니다.ROI 헤드 (ROI Heads): ROI 헤드는 제안된 상자를 사용하여 객체 인식을 수행합니다. 이 부분에는 박스 헤드, 마스크 헤드와 같은 다양한 하위 클래스가 포함되어 있습니다.
메타 아키텍처 (Meta Architecture)
Detectron2의 구조는 메타 아키텍처인 GeneralizedRCNN에서 정의됩니다. 이 메타 아키텍처는 백본 네트워크, RPN, ROI 헤드를 결합하여 객체 검출 모델을 형성합니다.
다양한 기능 및 모델
Detectron2는 다양한 내장 모델과 기능을 제공합니다. 이 중에서 일부는 Faster R-CNN, RetinaNet, Mask R-CNN, Cascade R-CNN, Keypoint R-CNN, Panoptic Segmentation 및 Large Vocabulary Instance Segmentation(LVIS)와 같은 모델을 포함합니다. 또한 다양한 데이터셋 및 학습 설정을 지원하여 사용자 정의 실험을 용이하게 합니다.
코드 구조
Detectron2의 코드 구조는 다음과 같이 구성되어 있으며, 체크포인트, 설정, 데이터 처리, 학습 엔진, 평가자 및 모델 구조를 관리합니다.
checkpoints: 체크포인트 및 모델 카탈로그 핸들러
config: 기본 구성 및 핸들러
data: 데이터셋 핸들러 및 데이터 로더
engine: 예측자 및 트레이너 엔진
evaluation: 각 데이터셋에 대한 평가자
export: Detectron2 모델을 Caffe2 (ONNX)로 변환
layers: 사용자 정의 레이어 (예: 변형 가능한 변환)
model_zoo: 사전 훈련된 모델 링크 및 핸들러
modeling: 모델링 관련 코드 (메타 아키텍처, 백본 네트워크, 제안 네트워크, ROI 헤드)
solver: 최적화 및 스케줄러 빌더
structures: 구조 클래스 (예: 상자, 인스턴스 등)
utils: 유틸리티 모듈 (예: 시각화 장치, 로거, 등)
Detectron2의 구조는 확장 가능하며, 사용자는 다양한 모델 및 데이터셋을 통합하고 실험을 수행할 수 있습니다.
Detectron2는 객체 검출 및 세그멘테이션 작업을 위한 강력한 도구로서, 컴퓨터 비전 연구 및 응용 프로그램 개발에 유용합니다. 이러한 다양한 기능과 구조는 사용자에게 유연성과 효율성을 제공합니다.
링크를 통해 코드 확인 가능
https://colab.research.google.com/github/whitechocobread/Ai-project/blob/main/2%EC%A3%BC%EC%B0%A8/Detectron2_Tutorial_ipynb.ipynb#scrollTo=OpLg_MAQGPUT
Detectron2_Tutorial_ipynb.ipynb
Run, share, and edit Python notebooks
colab.research.google.com
참고
https://medium.com/@hirotoschwert/digging-into-detectron-2-47b2e794fabd
Digging into Detectron 2
Part 1: Basic network architecture and repo structure
medium.com