Speech Command Classification with torchaudio
1. 필요 라이브러리 설치
# Uncomment the line corresponding to your "runtime type" to run in Google Colab
# CPU:
# !pip install pydub torch==1.7.0+cpu torchvision==0.8.1+cpu torchaudio==0.7.0 -f https://download.pytorch.org/whl/torch_stable.html
# GPU:
!pip install pydub torch==1.7.0+cu101 torchvision==0.8.1+cu101 torchaudio==0.7.0 -f https://download.pytorch.org/whl/torch_stable.html
import torch
import torch.nn as nn
import torch.nn.functional as F
import torch.optim as optim
import torchaudio
import sys
import matplotlib.pyplot as plt
import IPython.display as ipd
from tqdm import tqdm
> Error 해결(파이썬 버전 문제 해결)
#파이썬 버전 변경 3.10.12 -> 3.8.6
#ERROR: Could not find a version that satisfies the requirement torch==1.7.0+cpu (from versions: 0.1.2, 0.1.2.post1, 0.1.2.post2)
#ERROR: No matching distribution found for torch==1.7.0+cpu 해결
!wget https://www.python.org/ftp/python/3.8.6/Python-3.8.6.tgz > /dev/null 2>&1
!tar xvfz Python-3.8.6.tgz > /dev/null 2>&1
!Python-3.8.6/configure > /dev/null 2>&1
!make > /dev/null 2>&1
!sudo make install > /dev/null 2>&1
> Python 패키지 설치 중에 발생할 수 있는 오류 해결
#ERROR: command errored out with exit status 1 python setup.py egg_info 해결
!pip install --upgrade setuptools
2. 데이터 가져오기
# SpeechCommands 데이터세트 가져오기
from torchaudio.datasets import SPEECHCOMMANDS
import os
class SubsetSC(SPEECHCOMMANDS):
def __init__(self, subset: str = None):
super().__init__("./", download=True)
def load_list(filename):
filepath = os.path.join(self._path, filename)
with open(filepath) as fileobj:
return [os.path.normpath(os.path.join(self._path, line.strip())) for line in fileobj]
if subset == "validation":
self._walker = load_list("validation_list.txt")
elif subset == "testing":
self._walker = load_list("testing_list.txt")
elif subset == "training":
excludes = load_list("validation_list.txt") + load_list("testing_list.txt")
excludes = set(excludes)
self._walker = [w for w in self._walker if w not in excludes]
# Create training and testing split of the data. We do not use validation in this tutorial.
train_set = SubsetSC("training")
test_set = SubsetSC("testing")
waveform, sample_rate, label, speaker_id, utterance_number = train_set[0]
#웨이브폼 (waveform):시간에 따른 오디오 신호의 변화를 표현하는 시각적인 그래픽
print("Shape of waveform: {}".format(waveform.size()))
print("Sample rate of waveform: {}".format(sample_rate))
plt.plot(waveform.t().numpy());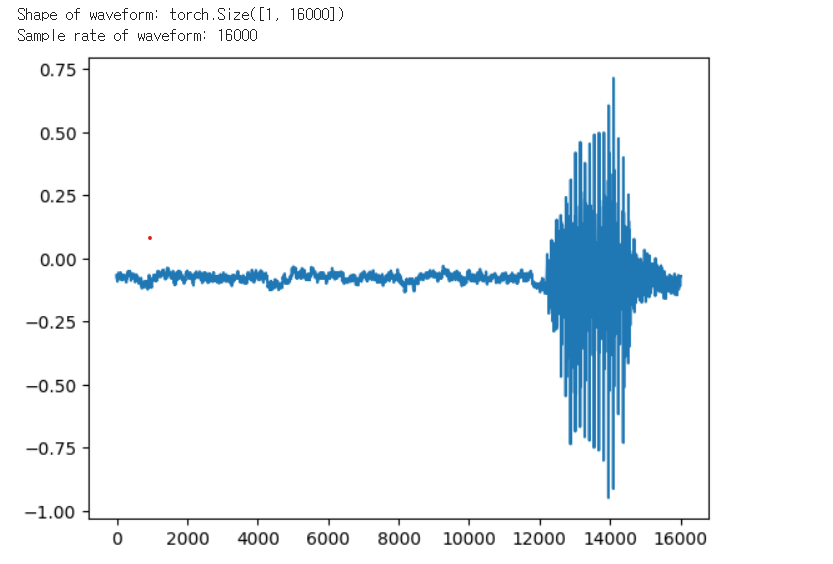
데이터세트에서 사용 가능한 label 목록을 찾기
import pandas as pd
# 주어진 라벨 리스트
labels = sorted(list(set(datapoint[2] for datapoint in train_set)))
# 데이터 프레임으로 변환
labels_df = pd.DataFrame({'Labels': labels})
# 데이터 프레임 출력
print(labels_df)
처음 몇 개의 파일은 사람들이 "backward"라고 말하는 것입니다.
waveform_first, *_ = train_set[0]
ipd.Audio(waveform_first.numpy(), rate=sample_rate)
waveform_second, *_ = train_set[1]
ipd.Audio(waveform_second.numpy(), rate=sample_rate)
마지막 파일에는 "zero"이라고 말하는 사람이 있습니다.
waveform_last, *_ = train_set[-1]
ipd.Audio(waveform_last.numpy(), rate=sample_rate)
3. Formatting the Data(전처리)
torchaudio.transforms.Resample 변환을 사용하여 오디오 데이터의 샘플링 레이트를 변경
#transform 객체를 사용하여 데이터를 새로운 샘플 속도로 다시 샘플링함
new_sample_rate = 8000
transform = torchaudio.transforms.Resample(orig_freq=sample_rate, new_freq=new_sample_rate)
transformed = transform(waveform)
레이블 목록의 인덱스를 사용하여 각 단어를 인코딩합니다
#레이블 목록의 인덱스를 사용하여 각 단어를 인코딩
def label_to_index(word):
# Return the position of the word in labels
return torch.tensor(labels.index(word))
def index_to_label(index):
# Return the word corresponding to the index in labels
# This is the inverse of label_to_index
return labels[index]
word_start = "yes"
index = label_to_index(word_start)
word_recovered = index_to_label(index)
print(word_start, "-->", index, "-->", word_recovered)
오디오 녹음과 발화로 구성된 데이터 포인트 목록을 모델에 적합한 두 개의 배치된 텐서로 변환하기 위해, PyTorch의 DataLoader가 배치 단위로 데이터셋을 순회할 수 있도록 하는 'collate function'을 구현
| collate function에서는 리샘플링과 텍스트 인코딩도 적용합니다. 이 함수는 데이터를 모델이 처리할 수 있는 형태로 준비하는 과정에서 중요한 역할을 하며, 데이터셋을 효율적으로 불러오고 전처리하는 데 사용됩니다. |
.
#리샘플링과 텍스트 인코딩
def pad_sequence(batch):
# Make all tensor in a batch the same length by padding with zeros
batch = [item.t() for item in batch]
batch = torch.nn.utils.rnn.pad_sequence(batch, batch_first=True, padding_value=0.)
return batch.permute(0, 2, 1)
def collate_fn(batch):
# A data tuple has the form:
# waveform, sample_rate, label, speaker_id, utterance_number
tensors, targets = [], []
# Gather in lists, and encode labels as indices
for waveform, _, label, *_ in batch:
tensors += [waveform]
targets += [label_to_index(label)]
# Group the list of tensors into a batched tensor
tensors = pad_sequence(tensors)
targets = torch.stack(targets)
return tensors, targets
batch_size = 256
if device == "cuda":
num_workers = 1
pin_memory = True
else:
num_workers = 0
pin_memory = False
train_loader = torch.utils.data.DataLoader(
train_set,
batch_size=batch_size,
shuffle=True,
collate_fn=collate_fn,
num_workers=num_workers,
pin_memory=pin_memory,
)
test_loader = torch.utils.data.DataLoader(
test_set,
batch_size=batch_size,
shuffle=False,
drop_last=False,
collate_fn=collate_fn,
num_workers=num_workers,
pin_memory=pin_memory,
)
4.Define the Network
이 튜토리얼에서는 원시 오디오 데이터 처리를 위해 컨볼루션 신경망(CNN)을 사용합니다. 일반적으로 오디오 데이터에 고급 변환을 적용하지만, 이 경우 CNN을 활용해 원시 데이터를 효과적으로 처리할 수 있습니다. 이 모델은 M5 네트워크 아키텍처를 기반으로 하며, 원시 오디오 데이터 처리 모델의 중요한 요소 중 하나인 첫 번째 계층 필터의 수용 필드 크기에 주목합니다.
모델의 첫 필터 길이는 80으로, 8kHz에서 샘플링된 오디오를 처리할 때 약 10ms의 수용 필드를 가집니다(4kHz에서는 약 20ms). 이 수용 필드 크기는 20ms에서 40ms 범위의 수용 필드를 사용하는 음성 처리 응용 프로그램과 유사합니다. 이러한 접근 방식은 CNN이 원시 오디오 데이터를 정확하게 처리하는 데 효과적임을 보여줍니다.
#M5 네트워크 아키텍처 모델
class M5(nn.Module):
def __init__(self, n_input=1, n_output=35, stride=16, n_channel=32):
super().__init__()
self.conv1 = nn.Conv1d(n_input, n_channel, kernel_size=80, stride=stride)
self.bn1 = nn.BatchNorm1d(n_channel)
self.pool1 = nn.MaxPool1d(4)
self.conv2 = nn.Conv1d(n_channel, n_channel, kernel_size=3)
self.bn2 = nn.BatchNorm1d(n_channel)
self.pool2 = nn.MaxPool1d(4)
self.conv3 = nn.Conv1d(n_channel, 2 * n_channel, kernel_size=3)
self.bn3 = nn.BatchNorm1d(2 * n_channel)
self.pool3 = nn.MaxPool1d(4)
self.conv4 = nn.Conv1d(2 * n_channel, 2 * n_channel, kernel_size=3)
self.bn4 = nn.BatchNorm1d(2 * n_channel)
self.pool4 = nn.MaxPool1d(4)
self.fc1 = nn.Linear(2 * n_channel, n_output)
def forward(self, x):
x = self.conv1(x)
x = F.relu(self.bn1(x))
x = self.pool1(x)
x = self.conv2(x)
x = F.relu(self.bn2(x))
x = self.pool2(x)
x = self.conv3(x)
x = F.relu(self.bn3(x))
x = self.pool3(x)
x = self.conv4(x)
x = F.relu(self.bn4(x))
x = self.pool4(x)
x = F.avg_pool1d(x, x.shape[-1])
x = x.permute(0, 2, 1)
x = self.fc1(x)
return F.log_softmax(x, dim=2)
model = M5(n_input=transformed.shape[0], n_output=len(labels))
model.to(device)
print(model)
def count_parameters(model):
return sum(p.numel() for p in model.parameters() if p.requires_grad)
n = count_parameters(model)
print("Number of parameters: %s" % n)
최적화
>가중치 감소를 0.0001로 설정한 Adam 최적화 프로그램을 사용
>처음에는 학습률 0.01로 학습하지만, 20 에포크 이후 학습 중에는 스케줄러를 사용하여 학습률을 0.001로 줄입니다.
# Adam 최적화
optimizer = optim.Adam(model.parameters(), lr=0.01, weight_decay=0.0001)
scheduler = optim.lr_scheduler.StepLR(optimizer, step_size=20, gamma=0.1) # reduce the learning after 20 epochs by a factor of 10
5.Training and Testing the Network
이제 모델에 훈련 데이터를 공급하고, 역전파 및 최적화 단계를 수행할 훈련 함수를 정의해보겠습니다. 훈련에 사용될 손실 함수는 음의 로그 가능도(negative log-likelihood)입니다. 이 네트워크는 각 에폭(epoch)이 끝날 때마다 테스트되어 훈련 과정 중 정확도가 어떻게 변하는지 확인할 수 있습니다. 이 방법을 통해 모델의 성능과 학습 과정을 지속적으로 평가하고 개선할 수 있습니다.
#train 함수가 각 에포크에서의 훈련 손실의 평균을 반환하도록 변수
def train(model, epoch, log_interval):
model.train()
total_loss = 0 # 훈련 중 누적된 손실을 추적하기 위한 변수
for batch_idx, (data, target) in enumerate(train_loader):
data = data.to(device)
target = target.to(device)
data = transform(data)
output = model(data)
loss = F.nll_loss(output.squeeze(), target)
optimizer.zero_grad()
loss.backward()
optimizer.step()
total_loss += loss.item()
if batch_idx % log_interval == 0:
print(f"Train Epoch: {epoch} [{batch_idx * len(data)}/{len(train_loader.dataset)} ({100. * batch_idx / len(train_loader):.0f}%)]\tLoss: {loss.item():.6f}")
pbar.update(pbar_update)
losses.append(loss.item())
# 훈련 중 누적된 손실의 평균을 반환
return total_loss / len(train_loader)
훈련 함수를 정의한 후, 이제 네트워크의 정확도를 테스트하는 함수를 만들어야 합니다. 모델을 eval() 모드로 설정한 다음, 테스트 데이터셋에 대한 추론을 실행합니다. eval()을 호출하면 네트워크의 모든 모듈에서 훈련 변수가 false로 설정됩니다. 배치 정규화(batch normalization)나 드롭아웃(dropout)과 같은 특정 레이어는 훈련 중에 다르게 작동하므로, 이 단계는 정확한 결과를 얻기 위해 매우 중요합니다. 이를 통해 모델이 실제 사용 환경에서 어떻게 작동하는지 평가할 수 있습니다.
#테스트 기능: 네트워크 정확도를 테스트하기 위한 기능
def number_of_correct(pred, target):
# count number of correct predictions
return pred.squeeze().eq(target).sum().item()
def get_likely_index(tensor):
# find most likely label index for each element in the batch
return tensor.argmax(dim=-1)
def test(model, epoch):
model.eval()
correct = 0
for data, target in test_loader:
data = data.to(device)
target = target.to(device)
# apply transform and model on whole batch directly on device
data = transform(data)
output = model(data)
pred = get_likely_index(output)
correct += number_of_correct(pred, target)
# update progress bar
pbar.update(pbar_update)
print(f"\nTest Epoch: {epoch}\tAccuracy: {correct}/{len(test_loader.dataset)} ({100. * correct / len(test_loader.dataset):.0f}%)\n")
마지막으로 네트워크를 훈련하고 테스트할 수 있습니다. 우리는 10개의 에포크 동안 네트워크를 훈련한 다음 학습률을 줄이고 10개의 에포크 동안 더 훈련할 것입니다. 각 에포크 후에 네트워크를 테스트하여 훈련 중에 정확도가 어떻게 변하는지 확인합니다.
> 2에포크인 경우


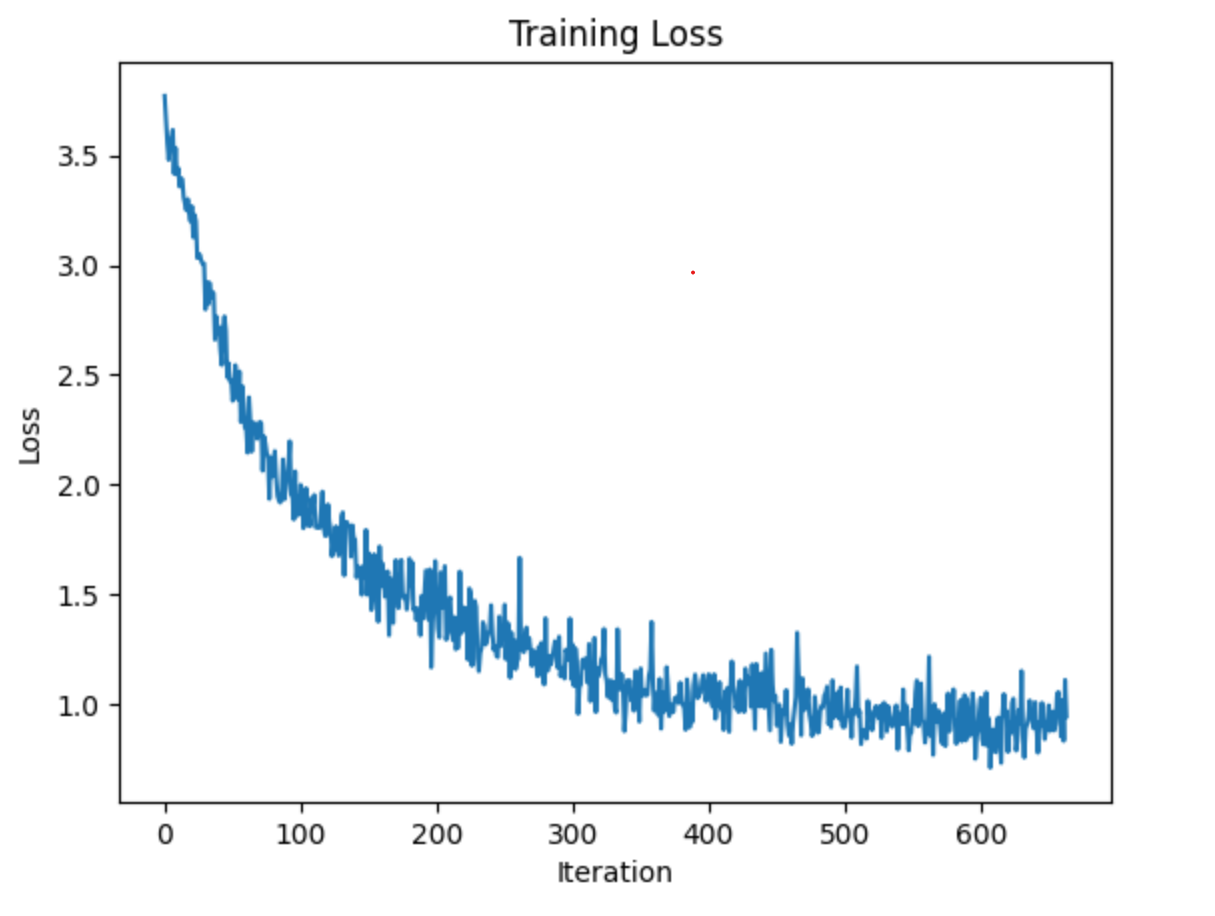
> 21에포크인 경우
Test Epoch: 18 Accuracy: 8918/11005 (81%)
Test Epoch: 19 Accuracy: 8873/11005 (81%)
Test Epoch: 20 Accuracy: 8902/11005 (81%)
Test Epoch: 21 Accuracy: 9477/11005 (86%)
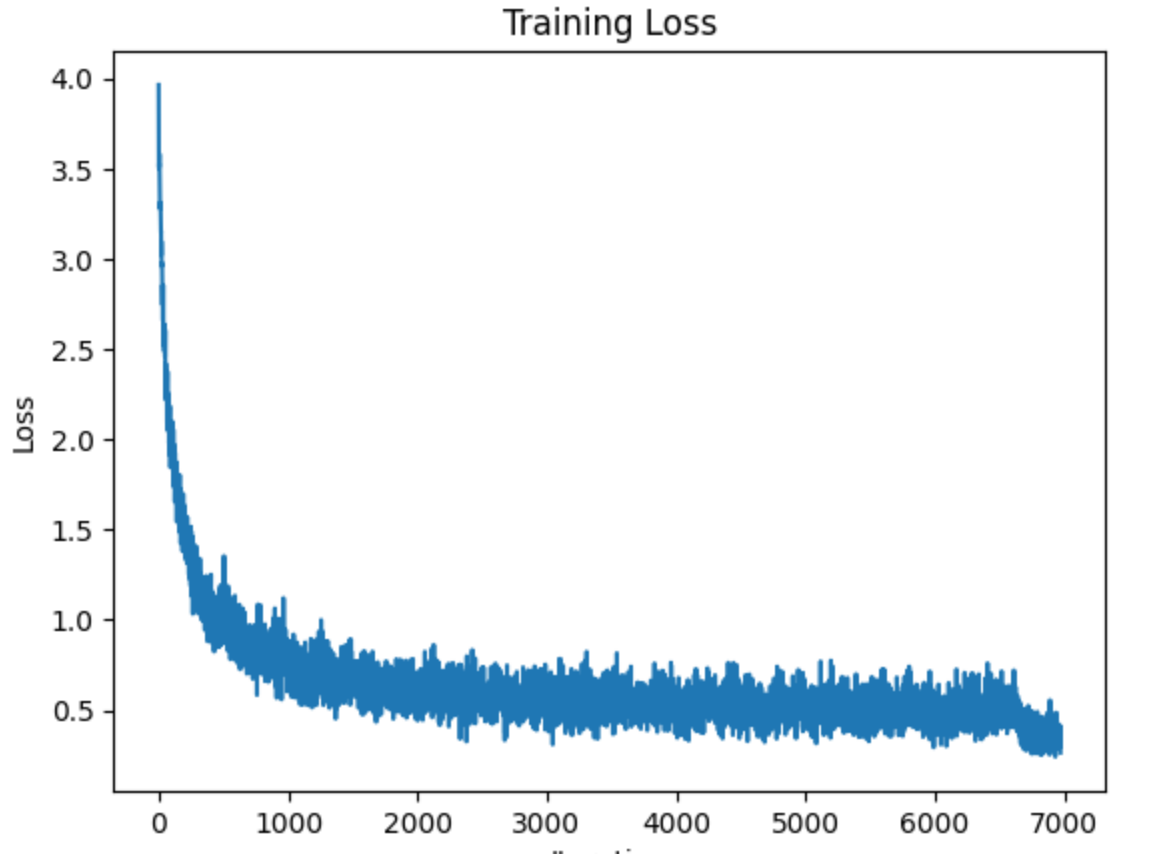
Early Stopping을 쓸 경우
import numpy as np
import matplotlib.pyplot as plt
from tensorflow.keras.callbacks import EarlyStopping, ModelCheckpoint
log_interval = 20
n_epoch = 21
patience = 5
best_val_loss = np.inf
counter = 0
pbar_update = 1 / (len(train_loader) + len(test_loader))
losses = []
transform = transform.to(device)
for epoch in range(1, n_epoch + 1):
train_loss = train(model, epoch, log_interval)
losses.append(train_loss)
val_loss = test(model, epoch)
if val_loss is not None and val_loss < best_val_loss: # Check if val_loss is not None
best_val_loss = val_loss
counter = 0
else:
counter += 1
if counter >= patience:
print(f"Early stopping after {epoch} epochs.")
break
scheduler.step()
plt.plot(losses)
plt.title("Training Loss")
plt.xlabel("Iteration")
plt.ylabel("Loss")
plt.show()Test Epoch: 1 Accuracy: 8404/11005 (76%)Test Epoch: 2 Accuracy: 8637/11005 (78%)Test Epoch: 3 Accuracy: 8286/11005 (75%)Test Epoch: 4 Accuracy: 8503/11005 (77%)Test Epoch: 5 Accuracy: 8518/11005 (77%)
Early stopping after 5 epochs.
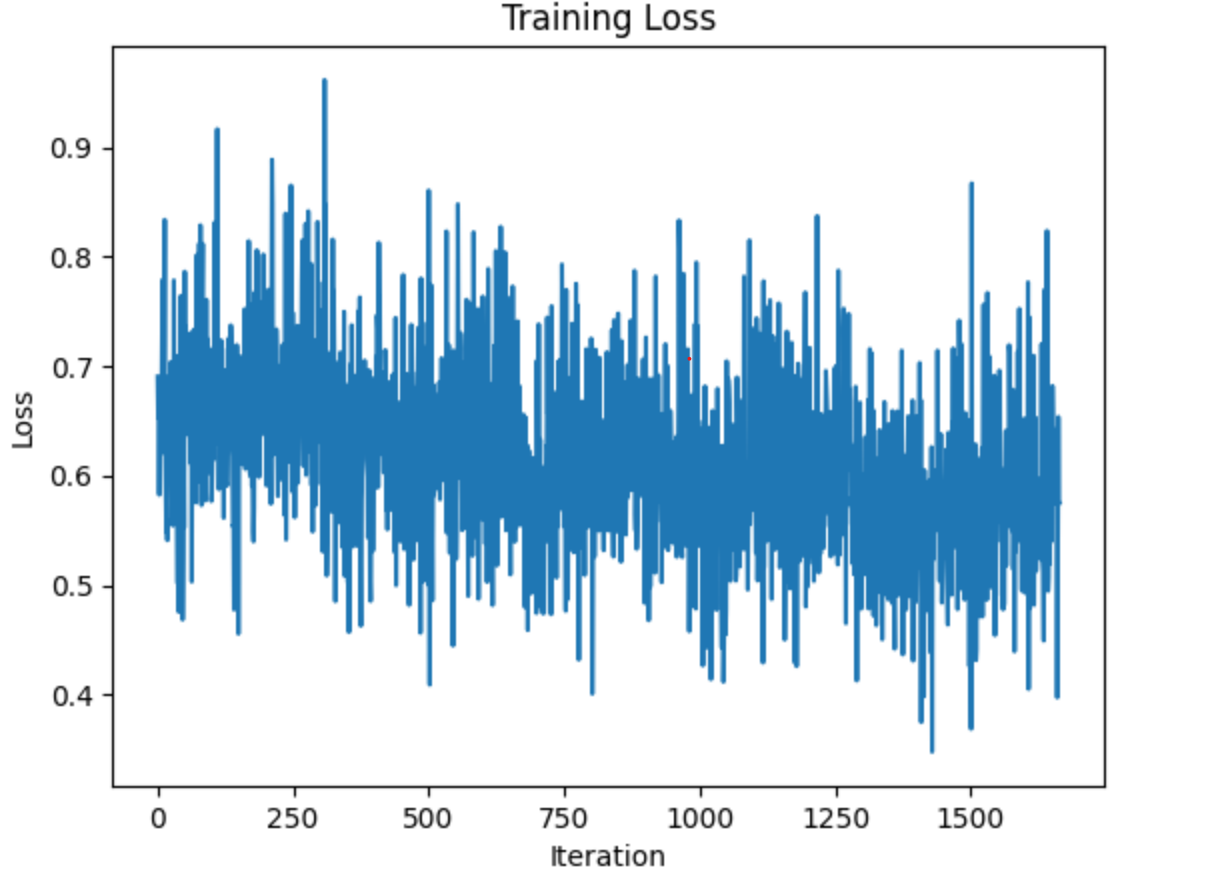
네트워크는 2개의 에포크 후에는 테스트 세트에서 65% 이상 정확해야 하며, 21개의 에포크 후에는 85% 이상 정확해야 합니다. 기차 세트의 마지막 단어를 살펴보고 모델이 어떻게 작동하는지 살펴보겠습니다.
PyTorch를 사용하여 오디오 waveform(음파 형태)의 라벨을 예측
def predict(tensor):
# Use the model to predict the label of the waveform
tensor = tensor.to(device)
tensor = transform(tensor)
tensor = model(tensor.unsqueeze(0))
tensor = get_likely_index(tensor)
tensor = index_to_label(tensor.squeeze())
return tensor
waveform, sample_rate, utterance, *_ = train_set[-1]
ipd.Audio(waveform.numpy(), rate=sample_rate)
print(f"Expected: {utterance}. Predicted: {predict(waveform)}.")Expected: zero. Predicted: zero.
PyTorch를 사용하여 오디오 데이터셋(test_set)에서 오디오 샘플을 반복적으로 평가하고, 모델이 잘못 분류한 첫 번째 예제를 찾는 과정입니다.
for i, (waveform, sample_rate, utterance, *_) in enumerate(test_set):
output = predict(waveform)
if output != utterance:
ipd.Audio(waveform.numpy(), rate=sample_rate)
print(f"Data point #{i}. Expected: {utterance}. Predicted: {output}.")
break
else:
print("All examples in this dataset were correctly classified!")
print("In this case, let's just look at the last data point")
ipd.Audio(waveform.numpy(), rate=sample_rate)
print(f"Data point #{i}. Expected: {utterance}. Predicted: {output}.")Data point #1. Expected: right. Predicted: nine.
import sys
sys.path
Error해결
#ModuleNotFoundError: No module named 'pydub'문제 해결
#"pydub" 패키지의 경로가 경로 리스트에 없어서, 필요한 경로를 직접 추가
sys.path.append('/usr/local/lib/python3.8/site-packages')
Python 스크립트
def record(seconds=3):
from google.colab import output as colab_output
from base64 import b64decode
from io import BytesIO
from pydub import AudioSegment
RECORD = (
b"const sleep = time => new Promise(resolve => setTimeout(resolve, time))\n"
b"const b2text = blob => new Promise(resolve => {\n"
b" const reader = new FileReader()\n"
b" reader.onloadend = e => resolve(e.srcElement.result)\n"
b" reader.readAsDataURL(blob)\n"
b"})\n"
b"var record = time => new Promise(async resolve => {\n"
b" stream = await navigator.mediaDevices.getUserMedia({ audio: true })\n"
b" recorder = new MediaRecorder(stream)\n"
b" chunks = []\n"
b" recorder.ondataavailable = e => chunks.push(e.data)\n"
b" recorder.start()\n"
b" await sleep(time)\n"
b" recorder.onstop = async ()=>{\n"
b" blob = new Blob(chunks)\n"
b" text = await b2text(blob)\n"
b" resolve(text)\n"
b" }\n"
b" recorder.stop()\n"
b"})"
)
RECORD = RECORD.decode("ascii")
print(f"Recording started for {seconds} seconds.")
display(ipd.Javascript(RECORD))
s = colab_output.eval_js("record(%d)" % (seconds * 1000))
print("Recording ended.")
b = b64decode(s.split(",")[1])
fileformat = "wav"
filename = f"_audio.{fileformat}"
AudioSegment.from_file(BytesIO(b)).export(filename, format=fileformat)
return torchaudio.load(filename)
# Detect whether notebook runs in google colab
if "google.colab" in sys.modules:
waveform, sample_rate = record()
print(f"Predicted: {predict(waveform)}.")
ipd.Audio(waveform.numpy(), rate=sample_rate)
ipd.Audio(transformed.numpy(), rate=new_sample_rate)Deep Speech: Scaling up end-to-end speech recognition
이 논문에서는 End-to-End 딥러닝을 이용해 개발된 최첨단 음성 인식 시스템을 소개합니다.
이 아키텍처는 기존의 전통적인 음성 인식 시스템보다 훨씬 단순한 구조를 가지고 있으며, 전통적인 시스템들이 소음 환경에서 성능이 떨어지는 문제를 해결했습니다. 본 시스템은 배경 소음, 잔향, 발화자 변화 등을 모델링하기 위해 수작업으로 설계된 구성요소가 필요 없으며, 직접 이러한 효과에 강건한 함수를 학습합니다. 또한, 음소 사전이나 음소라는 개념조차 필요하지 않습니다.
이 접근법의 핵심은 여러 GPU를 사용하는 잘 최적화된 RNN 트레이닝 시스템과, 효율적으로 대량의 다양한 트레이닝 데이터를 얻기 위한 새로운 데이터 합성 기술 세트입니다. 이 시스템, 'Deep Speech'라고 불리는 이 시스템은 널리 연구된 Switchboard Hub5'00에서 이전에 발표된 결과들을 능가하여 전체 테스트 세트에서 16.0%의 오류율을 달성했습니다. 또한, Deep Speech는 시중에서 널리 사용되는 최첨단 상용 음성 인식 시스템보다 소음이 심한 환경에서 더 나은 성능을 보입니다.
RNN Training Setup
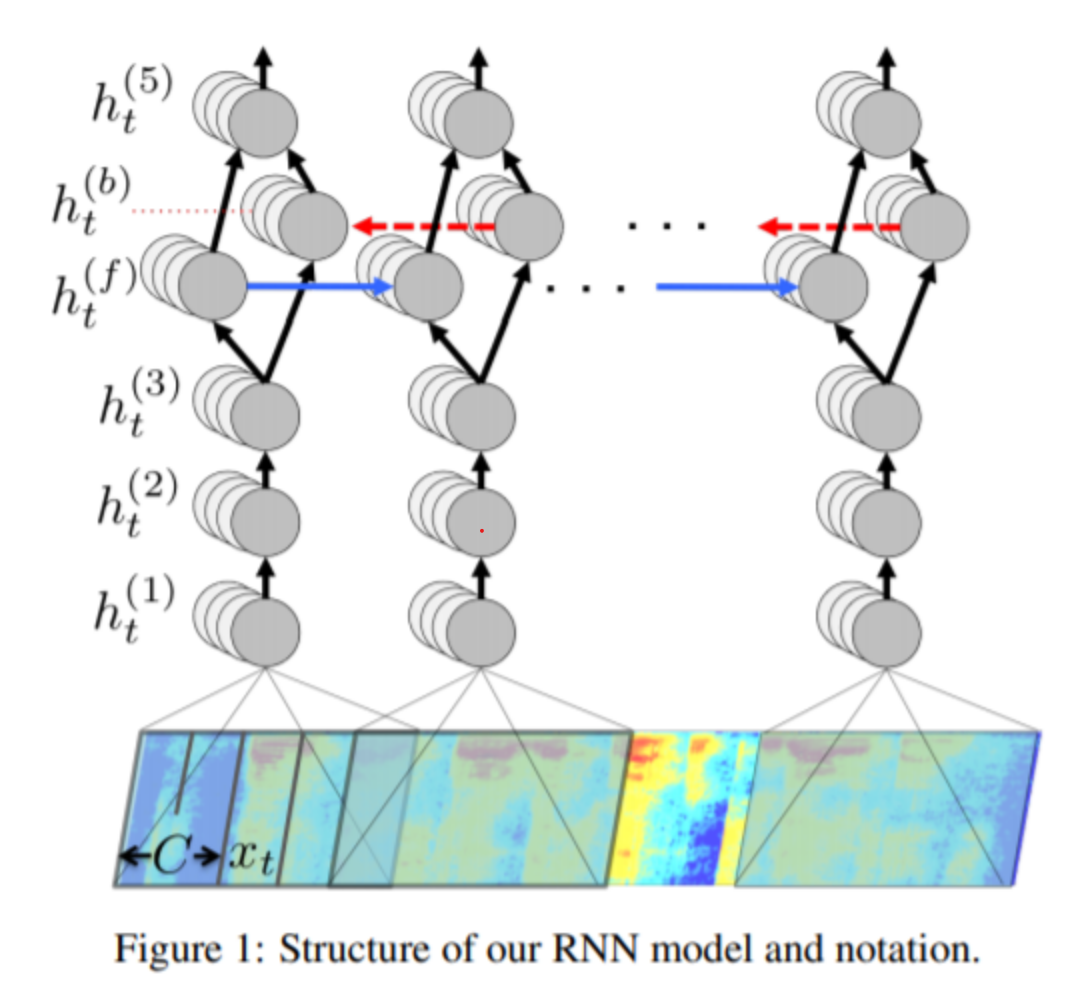
해당 챕터에서는 자신들이 어떤 식으로 모델을 구성했는지에 대해 설명합니다.
모델의 핵심은 RNN으로 구성되어 있으며, 트레이닝 셋은 (x1,y1),(x2,y2),...(xt,yt) 와 같은 딕셔너리 형식으로 구성합니다. (x는 스펙트로그램, y는 문자로 구성 )
핵심은 음성 스펙트로그램을 입력받아 영어 텍스트 전사본을 생성하는 순환 신경망(RNN)입니다. 이 시스템은 입력 시퀀스 x를 문자 확률 시퀀스로 변환하여, 전사 y를 예측합니다. 이 모델은 5개의 은닉층으로 구성되어 있으며, 처음 세 개의 층은 순환적이지 않습니다. 첫 번째 층은 각 시간 t에서 주변 C 프레임과 함께 스펙트로그램 프레임 xt에 따라 달라집니다. 나머지 비순환 층들은 각 시간 단계마다 독립적으로 작동합니다.
수치해석
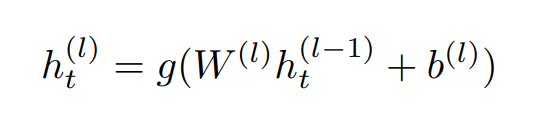
이 수식은 신경망의 한 층(l)에서의 은닉 유닛(h(l)t)을 계산하는 방법을 나타냅니다. 여기서 g는 활성화 함수, W(l)은 가중치 행렬, b(l)은 편향, h(l-1)t은 이전 층의 은닉 유닛을 의미합니다.
구체적으로, 수식의 각 부분은 다음과 같습니다:
- h(l-1)t: 이전 층(l-1)에서의 은닉 유닛입니다. 이 값은 신경망의 이전 층의 출력이며, 현재 층의 입력으로 사용됩니다.
- W(l): 현재 층(l)의 가중치 행렬입니다. 이 행렬은 입력 데이터와 곱해져 신경망의 학습 가능한 매개변수 중 하나입니다.
- b(l): 현재 층(l)의 편향입니다. 편향은 각 뉴런의 출력에 추가되는 상수값으로, 역시 학습 가능한 매개변수입니다.
- g: 활성화 함수입니다. 이 함수는 신경망이 비선형적 특성을 학습할 수 있도록 도와줍니다. 예를 들어 ReLU(Rectified Linear Unit) 함수는 자주 사용되는 활성화 함수 중 하나입니다.
이 수식은 각 은닉 유닛의 출력을 계산하는 데 사용되며, 신경망의 각 층에서 반복적으로 수행됩니다. 이렇게 계산된 출력은 다음 층의 입력으로 사용되거나, 최종 층에서는 신경망의 최종 출력을 생성하는 데 사용됩니다.
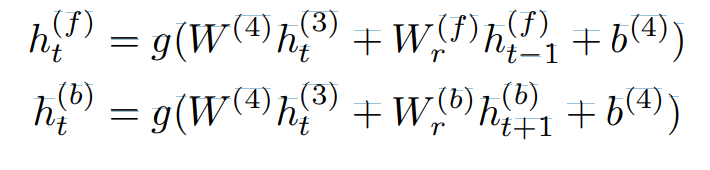
이 수식은 신경망의 네 번째 층은 양방향 순환 층(Bi-directional Recurrent Layer)으로 설명됩니다. 이 층은 두 가지 유형의 숨겨진 단위를 포함합니다: 하나는 순방향 순환을 가지는 단위(forward recurrence), 다른 하나는 역방향 순환을 가지는 단위(backward recurrence)입니다. 이 구조를 통해 신경망은 시간에 따른 정보를 양방향으로 처리하여 더 풍부한 시간적 문맥을 학습할 수 있습니다.
양방향 순환 신경망(Bi-directional Recurrent Neural Network)은 두 개의 순환 경로를 가지고 있으며, 하나는 정방향(h(f)t)을, 다른 하나는 역방향(h(b)t)을 나타냅니다.
- 정방향 순환(h(f)t):
- h(f)t는 시간 t에서의 정방향 순환 유닛의 출력을 나타냅니다.
- W(4)는 가중치 행렬로, 3번째 층의 출력(h(3)t)과 곱해집니다.
- W(f)r은 정방향 순환 유닛의 가중치 행렬로, 이전 시간 단계(t-1)의 정방향 순환 유닛의 출력(h(f)t−1)과 곱해집니다.
- b(4)는 편향입니다.
- g는 활성화 함수입니다.
- 역방향 순환(h(b)t):
- h(b)t는 시간 t에서의 역방향 순환 유닛의 출력을 나타냅니다.
- W(4)는 3번째 층의 출력(h(3)t)과 곱해지는 동일한 가중치 행렬입니다.
- W(b)r은 역방향 순환 유닛의 가중치 행렬로, 다음 시간 단계(t+1)의 역방향 순환 유닛의 출력(h(b)t+1)과 곱해집니다.
- b(4)는 편향입니다.
- g는 활성화 함수입니다.
양방향 순환 신경망은 각 시간 단계에서 입력 시퀀스의 정보를 양방향(과거와 미래)에서 모두 고려하여 처리합니다. 이를 통해 신경망은 더 풍부한 시간적 컨텍스트 정보를 활용할 수 있습니다. 이때 주의할 점으로는, forward는 t = 1 에서 t = T 방향으로 흐르고, backward는 t = T에서 t = 1 방향으로 흐른다는 점입니다.
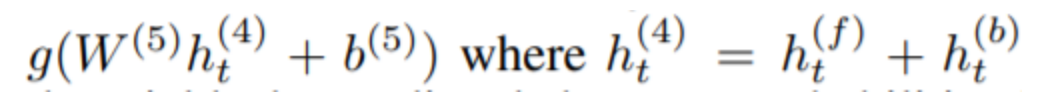
이 수식은 신경망의 다섯 번째 층(비순환 층)의 계산 방법을 설명하고 있습니다. 여기서 h(5)t는 다섯 번째 층에서의 출력을 나타내며, 다음과 같이 계산됩니다:
- h(4)t는 네 번째 층(양방향 순환 층)의 출력으로, 정방향(h(f)t)과 역방향(h(b)t) 유닛의 출력의 합입니다.
- W(5)는 다섯 번째 층의 가중치 행렬이고, b(5)는 편향 값입니다.
- g는 활성화 함수입니다. 이 경우에는 ReLU 함수나 다른 비선형 함수일 수 있습니다.
이렇게 계산된 h(5)t는 다음 층으로 전달되어 최종적인 예측을 위한 계산에 사용됩니다.
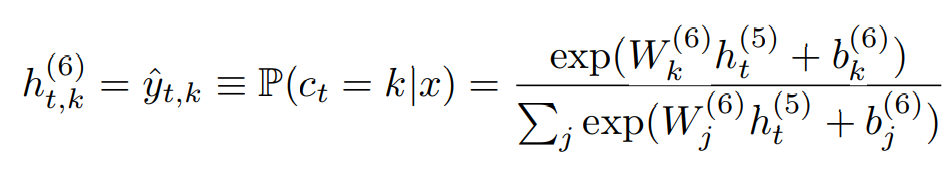
이 수식은 신경망의 출력 층에서 각 시간 단계(t)와 각 문자(k)에 대한 확률을 계산하는 방법을 나타냅니다.
- h(6)t,k는 시간 t에서 캐릭터 k에 대한 예측된 확률을 나타냅니다.
- P(ct = k|x)는 입력 x가 주어졌을 때, 시간 t에서 k가 나타날 확률을 의미합니다.
- exp(W(6)k h(5)t + b(6)k)는 소프트맥스 함수의 분자로, k번째 캐릭터에 대한 확률을 계산합니다. 여기서 W(6)k는 가중치 행렬의 k번째 열, b(6)k는 편향의 k번째 요소입니다.
- Pj exp(W(6)j h(5)t + b(6)j)는 소프트맥스 함수의 분모로, 모든 가능한 캐릭터에 대해 확률을 합산합니다.
이러한 방식으로 각 시간 단계에서 각 캐릭터의 출현 확률을 계산하고, 이를 바탕으로 최종적으로 음성 인식을 수행합니다.
요약하자면
- 네 번째 층(양방향 순환층):
- 순방향 은닉 유닛(h(f)t): 이전 시간 스텝 t-1의 순방향 은닉 유닛과 현재 시간 스텝 t의 입력을 기반으로 계산됩니다.
- 역방향 은닉 유닛(h(b)t): 다음 시간 스텝 t+1의 역방향 은닉 유닛과 현재 시간 스텝 t의 입력을 기반으로 계산됩니다.
- 순방향 은닉 유닛은 시간 순서대로 계산되며, 역방향 은닉 유닛은 역순으로 계산됩니다.
- 다섯 번째 층(비순환층):
- 이 층은 순방향과 역방향 은닉 유닛 모두를 입력으로 받습니다.
- 다섯 번째 층의 출력은 순방향과 역방향 유닛의 합을 기반으로 계산됩니다.
- 출력층(소프트맥스 함수):
- 출력층은 표준 소프트맥스 함수를 사용하여 각 시간 슬라이스 t와 문자 k에 대한 문자 확률을 예측합니다.
- 이 확률은 모델이 해당 시간에 특정 문자를 예측할 가능성을 나타냅니다.
- 여기서 사용된 가중치(W(6)k)와 편향(b(6)k)은 각 문자 k에 대응하는 출력층의 매개변수입니다.
연구
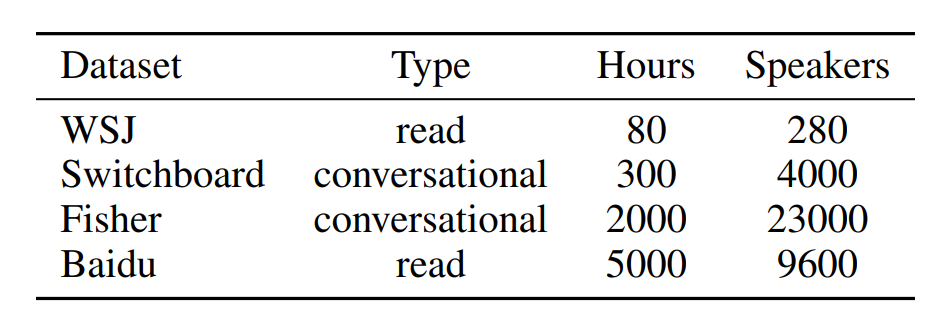
이 테이블을 통해 대규모 딥러닝 시스템은 풍부한 레이블이 붙은 데이터를 필요로 합니다.
음성 인식을 위해 방대한 텍스트 데이터를 기반으로 한 N-gram 언어 모델을 사용했습니다. 이 모델은 예를 들어 'arther'를 'are there'로, 'n tickets'를 'any tickets'로 같이 실제 발음에 가깝게 변환하는 역할을 합니다. 성능 향상을 위해 '빔 서치(beam search)' 기법을 사용했습니다. 이 방법에서는 빔의 크기를 1,000부터 8,000까지 상당히 크게 설정했습니다. 이는 다른 연구들에서 사용된 빔 크기가 일반적으로 수십 단위인 것과 비교했을 때 매우 큰 규모입니다. 이러한 큰 빔 크기를 사용함으로써 더 정확한 음성 인식 결과를 얻을 수 있었습니다.
전통적 기계 학습 접근 방식:
- 원시 입력 데이터에서 특징 생성:
- 도메인별 지식 활용: 각 작업에 맞는 차별적인 특징을 식별하기 위해 전문가의 지식이 필수적입니다.
- 특징 추출 과정: 원시 데이터에서 수동으로 특징을 추출하고, 이를 사용하여 모델을 학습시킵니다.
- 추출된 특징 사용:
- 전통적 알고리즘 활용: 추출된 특징을 기반으로 SVM, 결정 트리 등의 기계 학습 알고리즘을 사용하여 예측 모델을 구축합니다.
- 단점:
- 시간과 노력 소모: 수동 특징 추출과 도메인 지식에 기반한 접근 방식은 많은 시간과 노력을 요구합니다.
- 유연성 부족: 새로운 데이터 유형이나 변화에 빠르게 적응하기 어렵습니다.
엔드투엔드 딥 러닝 접근 방식:
- 직접적인 입력-출력 매핑 학습:
- 대규모 신경망 활용: 원시 데이터를 바로 신경망에 입력하여, 네트워크가 필요한 기능을 자동으로 학습하도록 합니다.
- 자동 특징 추출: 신경망은 입력 데이터를 처리하면서 예측에 필요한 관련 특징을 스스로 학습합니다.
- 자동화된 과정:
- 수동 엔지니어링 불필요: 수동 특징 추출이나 도메인별 전문 지식 없이도 효과적인 학습이 가능합니다.
- 시간과 노력 절약: 자동화된 학습 과정은 훨씬 더 빠르고 효율적입니다.
- 성공 요인:
- 대량 데이터 활용: 엄청난 양의 데이터를 사용하여 신경망이 고차원적인 특징을 학습할 수 있습니다.
- 신경망의 능력: 대규모 데이터에서 복잡한 패턴을 학습할 수 있는 신경망의 능력은 엔드투엔드 딥 러닝의 핵심입니다.
이러한 차이들은 데이터를 처리하는 방식과 학습 방법론에서 근본적인 전환을 의미합니다. 전통적 방식은 많은 수동 작업과 도메인 지식에 의존하지만, 엔드투엔드 딥 러닝은 이러한 제약을 넘어서 데이터 자체에서 직접적이고 자동화된 학습을 가능하게 합니다.
느낀점 : 이번 과제를 하며 음성인식에 대해 관심을 가지게 되었습니다. 관련 논문를 위주로 찾아보며 공부를하였습니다. 이제야 전공공부를 들어간 2학년 학부생입장에서는 이해하기 어려운 단어들이 많았습니다. 하지만 과제를 해나가는데 있어서 필요한 정보들을 정리해가면서 공부를 해나가니 AI라는 분야에 대해서 단순코딩을 배웠던 이전보다 딥하게 빠져들 수 있었던거 같습니다. 이번 과제로 통해 End-to-End 딥러닝을 조금이 나마 알게되었습니다
'AI기초프로젝트 과제' 카테고리의 다른 글
| AI기초프로젝트 3주차 과제 - Naver Shopping Review Sentiment Analysis (0) | 2023.11.06 |
|---|---|
| 기말 프로젝트 (0) | 2023.11.06 |
| AI기초프로젝트 5주차 과제 - 감성Fine-tuning (0) | 2023.10.22 |
| AI기초프로젝트 4주차 과제 - Transfer Learning for Computer Vision Tutorial (0) | 2023.10.22 |
| AI기초프로젝트 2주차 과제 - Detectron2 (0) | 2023.10.17 |



