감성분석 Fine-tuning해보기
AI기초 프로잭트 5주차 과제 -1
코랩에서 PyTorch와 Hugging Face Transformers 라이브러리를 사용하여 학습하였습니다.(GPU사용)
학습 과정 (데이터 전처리, 모델 구성, 학습)
1.데이터셋 다운로
먼저 HuggingFace Transformers 패키지를 설치한 다음, NSMC 데이터셋을 다운로드합니다. 데이터셋은 "ratings_train.txt"와 "ratings_test.txt" 두 개의 파일로 다운로드됩니다.
2.데이터 전처리
Naver Sentiment Movie Corpus (NSMC) 데이터셋을 PyTorch 모델 학습에 사용하기 위한 형식으로 로드하기 위해 정의되었습니다.
- 이 메서드는 데이터를 로드하고 전처리를 수행합니다.
- 이 메서드는 데이터셋의 전체 길이를 반환합니다. 즉, 데이터셋에 있는 샘플 수를 반환합니다.
- 이 메서드는 데이터셋에서 특정 인덱스 idx에 해당하는 샘플을 반환합니다.
3.모델 생성(ELECTRA 모델)
- pre-trained 모젤인 ElectraForSequenceClassification을 "monologg/koelectra-base-v3-discriminator"에서 가져오고 이 모델을 PyTorch 디바이스(일반적으로 GPU)로 이동시킵니다.
- ElectraForSequenceClassification 모델은 사전 훈련된 KoELECTRA 모델을 기반으로 하며, 파인 튜닝을 통해 한국어 감정 분류 작업에 맞게 세부 조정되었습니
ElectraForSequenceClassification 모델의 구조
ElectraModel:
- Embeddings 레이어: 입력 텍스트를 전처리하고 단어 임베딩, 위치 임베딩, 토큰 타입 임베딩 등을 생성하는 역할을 합니다.
- Encoder 레이어: 12개의 인코더 레이어로 구성되며, 각각은 Self-Attention, Intermediate, Output 서브-레이어를 가집니다. 이 인코더 레이어는 텍스트의 표현을 계층적으로 추출하고 변환합니다.
ElectraClassificationHead:
- Dense 레이어: 입력 피쳐를 출력 피쳐로 매핑하는 레이어로, 모델의 출력을 준비하는 역할을 합니다.
- Dropout 레이어: 드롭아웃을 적용하여 모델의 일반화를 도와주며, 과적합을 방지합니다.
- Out_proj 레이어: 출력을 분류 클래스 수에 대한 점수로 매핑하는 밀집 레이어로, 모델의 최종 출력을 얻게됩니다.
4.학습
- AdamW는 Adam 옵티마이저의 변형으로, 가중치 감쇠(weight decay)를 적용하여 모델의 가중치를 정규화합니다.
- 학습률(lr) =5e-6 설정합니다.
- 학습데이터와 테스트 데이터 미니배치(mini-batch) 단위로 모델에 공급하기 위한 데이터 로더(data loader)를 생성합니다. batch_size: 한 미니배치에 포함될 데이터 샘플의 수를 설정
- shuffle=True: 데이터를 에포크(epoch)마다 섞을 것인지를 나타냅니다. 섞는 것은 모델의 학습을 더 효과적으로 만들어주며, 데이터 순서에 따른 학습 편향을 방지합니다.
학습 결과
- train데이터셋
5 epochs / batch_size = 16 으로 학습
losses (손실):
- 에포크 1: 5874.16
- 에포크 2: 6339.00
- 에포크 3: 6337.42
- 에포크 4: 6334.99
- 에포크 5: 6336.21
accuracies (정확도):
- 에포크 1: 약 58.27%
- 에포크 2: 약 49.95%
- 에포크 3: 약 49.91%
- 에포크 4: 약 50.39%
- 에포크 5: 약 50.01%
주목할 점:
- 손실(loss)은 각 에포크마다 증가하는 경향이 있습니다.
- 정확도(accuracy)는 첫 번째 에포크에서 가장 높았으며 그 이후에는 큰 변화가 없었습니다.
- test 데이터셋
정확도: 약 50.27% 테스트 데이터 총 샘플 수: 3073개
결론
KoELECTRA는 NSMC 감성분석 모델로서는 성능이 낮다
ELECTRA
BERT의 한계를 극복하는 새로운 언어 모델
소개: BERT (Bidirectional Encoder Representations from Transformers)와 같은 Masked 언어 모델은 자연어 처리 분야에서 큰 주목을 받았습니다. 그러나 이러한 모델은 여전히 몇 가지 한계점을 가지고 있습니다.
Masked 언어 모델의 한계점:
- 데이터와 비용의 문제:
- Masked 언어 모델은 대량의 데이터와 모델 크기가 필요합니다. 모델이 대규모로 저장되어야 하므로 저장 공간과 비용이 높아집니다. 특히, pre-training을 위해 필요한 대규모 데이터셋은 구축 및 유지에 많은 비용이 발생합니다.
- 데이터 낭비:
- BERT와 같은 모델은 학습 과정에서 전체 데이터셋의 15% 정도만 가려서 학습합니다. 이로 인해 다른 토큰들은 낭비되는 것이 일반적입니다. 이것은 많은 데이터가 필요하다는 의미이며, 데이터의 일부가 효과적으로 활용되지 않는 문제를 야기합니다.
ELECTRA의 해결책:
- Replaced Token Detection:
- ELECTRA는 BERT와 같은 모델에서 데이터의 낭비 문제를 해결하기 위해 "Replaced Token Detection"이라고 하는 개념을 도입했습니다. 모델은 모든 토큰을 살펴보며 가짜 토큰과 실제 토큰을 구별하여 학습합니다. 이로써 데이터의 효율적인 활용이 가능해지며 모델의 성능 향상이 이루어집니다.
- Replaced Token Detection의 기본 구조

- 그림을 보면 일반적으로 generator는 discriminator에 비해 작은 구조를 갖고 있음을 알 수 있다. GAN과 비슷한 구조를 띄지만 maximum likelihood를 이용해 generator를 학습한다는 점에서 다릅니다. 사전학습이 끝나면, 생성 모델은 더이상 사용하지 않고, 판별 모델을 다운스트림 태스크에 대해 fine-tuning 한다.
- 비용 효율적 학습:
- ELECTRA 모델은 데이터의 더 효율적인 활용을 통해 BERT와 같은 모델에 비해 더 적은 데이터로도 학습이 가능해집니다. 이는 비용을 절감하고, 작은 규모의 데이터셋에서도 높은 성능을 얻을 수 있게 합니다.
ELECTRA 모델의 작동 원리와 구조
- 작동원리: ELECTRA는 Replaced Token Detection을 기반으로 입력 토큰 중 일부를 다른 토큰으로 교체하고 이를 판별하는 방식으로 학습합니다. Discriminator는 교체된 토큰을 판별하여 어떤 토큰이 실제로 교체된 "진짜" 토큰인지 "가짜" 토큰인지 판별합니다.
- 구조 ELECTRA 모델은 ELECTRA Layer, Embeddings, Encoder, 그리고 Classification Head로 구성됩니다. ELECTRA Layer에는 Self-Attention, Intermediate, Output 서브-레이어가 있으며, 입력 토큰의 판별 작업을 수행합니다.
- replaced token detection
mlm이 만들어낸 문장의 각 토큰이 원본데이터에 있는 토큰인지, 만들어낸 가짜 토큰인지 True, Flase로 판별한다. 모든 토큰을 다살펴야하고, 주변문맥을 다보게된다.
그래서 mlm이 학습하듯 문맥을 학습하게 되고 모든 토큰의 이진분류를 해야하기에 모든 토큰에 대한 loss를 구해야하고 즉 이는, 모든 데이터를 학습하는 효과가 있다.
ELECTRA vs. GAN: 텍스트 처리와 이미지 생성의 비교
유사성:
- ELECTRA와 GAN 모두 "discriminator"와 "generator" 개념을 공유합니다. 이러한 개념은 적대적 학습(Adversarial Learning)의 핵심입니다. ELECTRA의 Discriminator는 실제 토큰과 교체된 토큰을 판별하고, GAN의 Discriminator는 진짜 이미지와 가짜 이미지를 판별합니다. 두 모델 모두 discriminator가 더 나은 성능으로 생성된 데이터를 판별하도록 훈련됩니다.
차이점:
- ELECTRA는 텍스트 분류를 위해 학습됩니다. ELECTRA의 주요 목표는 문장 또는 문서의 감정 분류, 텍스트 분류, 텍스트의 긍정 또는 부정 판단과 같은 과제입니다. GAN은 이미지 생성 및 데이터 생성을 위해 사용됩니다. GAN은 이미지, 음성 등의 데이터 생성에 특히 유용합니다.
- GAN의 discriminator는 생성된 이미지를 진짜 또는 가짜로 판별합니다. discriminator가 진짜로 판별하면 generator에게 패널티를 주고, 가짜로 판별하면 generator가 더 나은 이미지를 생성하도록 유도됩니다.
- 반면, ELECTRA의 discriminator는 실제 텍스트 데이터와 생성된 텍스트 데이터를 구별합니다. ELECTRA의 목표는 잘 학습된 언어 모델을 통해 생성된 텍스트가 실제 텍스트와 구별되지 않도록 하는 것입니다. 이러한 discriminator는 "Masked Language Model"과 유사한 방식으로 작동합니다.
- GAN은 주로 생성적 모델로 사용되며, discriminator와 generator가 경쟁하여 생성된 데이터의 품질을 향상시킵니다. ELECTRA는 텍스트 분류 및 응용 프로그램의 성능 향상을 위해 사용됩니다.
모델의 학습 방식:
- GAN: Generator와 Discriminator 사이의 경쟁적 학습을 기반으로 합니다. Discriminator가 진짜와 가짜를 구별하도록 학습하고, generator는 discriminator를 속이도록 생성된 데이터를 개선합니다.
- ELECTRA: ELECTRA는 Masked Language Model(MLM)과 비슷한 방식으로, discriminator와 generator를 동시에 학습합니다. ELECTRA의 discriminator는 생성된 텍스트가 실제 텍스트와 구별되지 않도록 하려는 목표로 학습됩니다.
- Electra 과정
input --> mlm --> fake sentence --> Electra(True, False)
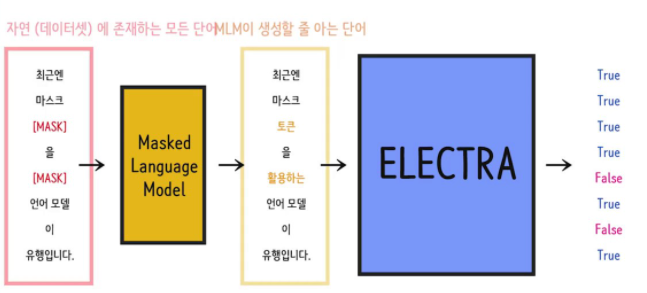
- masked model에서 기존 mlm은 학습시키는 모델론 transformer encoder 하나.
- Electra에서 기존 mlm은 학습시키는 모델론 transformer encoder 두 개.
- weight sharing은 파라미터 수를 줄이는 것 Electra에 적합 하지 않다.
=> mlm(like gener), electra(like discrim) 크기를 맞춰줘야만 모든 weight share이 가능했다. 하지만 이는 메모리에 부담이 돼서 임베딩에만 weight sharing 진행한다. mlm에서 학습해서 나온 값이 어떤 단어가 마음에 안들어서 생성을 하나도 하지 않았다면 electra는 그 단어를 튜닝할 수 없다. 임베딩이 편향적으로 될 수있다. (= generator에 의존적으로 되는 것) 그래서 임베딩층을 sharing 해주는 것이 효율이 좋았다.
# MLM(Masked Language Modeling) 언어 모델을 학습시키기 위한 자연어 처리 태스크 중 하나입니다. MLM의 주요 아이디어는 주어진 텍스트에서 일부 단어 또는 토큰을 가려놓고(마스크 처리), 모델이 이 가려진 단어를 예측하도록 하는 것입니다. MLM은 BERT와 같은 모델의 사전 훈련에 널리 사용됩니다.
참고 자료
모델( KoElectra-small 사용 )
https://github.com/monologg/KoELECTRA
GitHub - monologg/KoELECTRA: Pretrained ELECTRA Model for Korean
Pretrained ELECTRA Model for Korean. Contribute to monologg/KoELECTRA development by creating an account on GitHub.
github.com
데이터셋( 네이버 영화 리뷰 데이터셋 )
GitHub - e9t/nsmc: Naver sentiment movie corpus
Naver sentiment movie corpus. Contribute to e9t/nsmc development by creating an account on GitHub.
github.com
코드
https://colab.research.google.com/drive/1h5cP8xVcA5xFujVu5Qw83b8dzq5Ubz63#scrollTo=hc7P9wzHv0LE
Google Colaboratory Notebook
Run, share, and edit Python notebooks
colab.research.google.com
HuggingFace KoElectra로 NSMC 감성분류모델학습하기
HuggingFace에 박장원님이 학습해서 올려주신 KoElectra-small을 이용해서 NSMC(Naver Sentiment Movie Corpus) 감성문류 모델을 학습해본다. 학습은 Googel Colab(GPU)에서 Pytorch를…
heegyukim.medium.com
참조: ELECTRA: Pre-training Text Encoders as Discriminators Rather Than Generators( Kevin Clark, Minh-Thang Luong, Quoc V. Le, Christopher D. Manning )
'AI기초프로젝트 과제' 카테고리의 다른 글
| AI기초프로젝트 3주차 과제 - Naver Shopping Review Sentiment Analysis (0) | 2023.11.06 |
|---|---|
| 기말 프로젝트 (0) | 2023.11.06 |
| AI기초프로젝트 4주차 과제 - Transfer Learning for Computer Vision Tutorial (0) | 2023.10.22 |
| AI기초프로젝트 2주차 과제 - Detectron2 (0) | 2023.10.17 |
| AI기초프로젝트 1주차 과제 - 음성인식 (0) | 2023.10.17 |



