발전 과정

NLP 발전
- RNN (1986): 순환 신경망(Recurrent Neural Network)을 의미하며, 시퀀스 데이터 처리에 유용하게 사용되는 신경망의 한 형태입니다.
- LSTM (1997): 장단기 메모리(Long Short-Term Memory)를 의미하며, RNN의 한 변형으로, 시퀀스 데이터에서 장기 의존성 문제를 해결하기 위해 고안되었습니다.
- Seq2Seq (NIPS 2014): 시퀀스-투-시퀀스 모델로, 두 개의 RNN을 연결하여 하나는 입력 시퀀스를 처리하고 다른 하나는 출력 시퀀스를 생성하는 구조입니다.
- Attention (ICLR 2015): 어텐션 메커니즘은 주어진 문맥에서 중요한 부분에 '주목'하여 처리하는 기법으로, 시퀀스 모델의 성능을 향상시키는 데 도움을 줍니다.
- Transformer (NIPS 2017): 어텐션 메커니즘에 기반한 아키텍처로, 병렬 처리가 가능하며 Seq2Seq 모델과 비교했을 때 효율성과 성능 면에서 큰 개선을 이루었습니다.
- GPT-1 (2018): Generative Pretrained Transformer의 첫 번째 버전으로, 대량의 텍스트 데이터로 사전 학습된 후 특정 태스크에 대한 미세조정을 통해 다양한 언어 처리 작업을 수행할 수 있습니다.
- BERT (NAACL 2019): Bidirectional Encoder Representations from Transformers를 의미하며, 양방향 트랜스포머를 사용하여 텍스트의 양방향 컨텍스트를 학습합니다.
- GPT-3 (2020): GPT 시리즈의 세 번째 버전으로, 더 많은 데이터와 더 큰 모델 크기로 사전 학습된 후 다양한 언어 처리 작업에 사용됩니다.
차이점
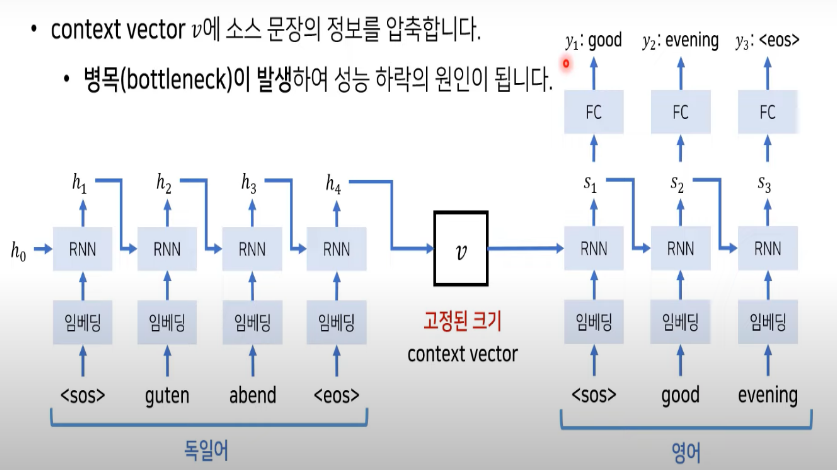
문제점: 이 모델은 소스 문장을 고정된 길이의 context vector에 인코딩합니다. 이는 "bottleneck"이 되어, 특히 긴 문장에서 정보 손실을 초래합니다. 모든 소스 정보를 하나의 고정된 크기의 벡터로 압축해야 하기 때문에, 모델이 긴 문장의 모든 정보를 유지하고 전달하는 데 한계가 있습니다.
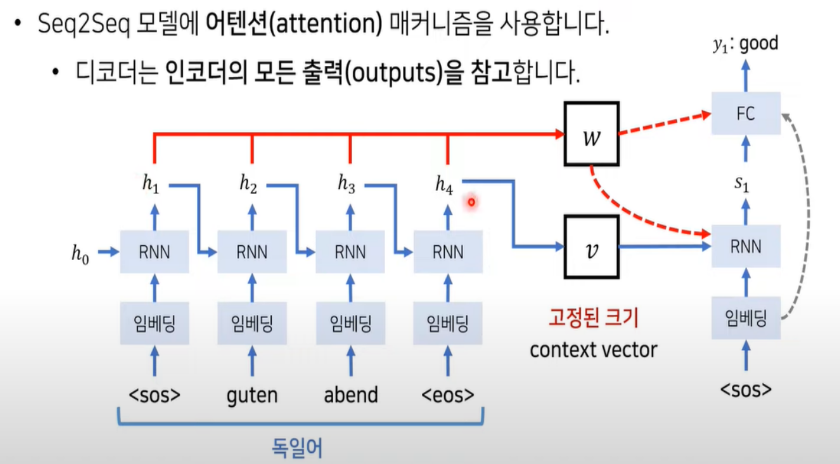
해결방법: 어텐션 메커니즘은 인코더의 모든 hidden states (h1, h2, h3, h4)에 가중치를 부여하여 디코더의 각 스텝에서 중요한 정보에 집중할 수 있게 합니다. 이를 통해 디코더는 필요한 정보에 "주목"하여 타겟 문장을 보다 정확하게 생성할 수 있습니다. 이 방법은 긴 문장에서도 정보를 보다 효과적으로 활용할 수 있게 해, 긴 시퀀스를 처리하는 데 있어서의 성능 문제를 해결했습니다. 즉, 각 디코딩 단계에서 입력 문장의 중요한 부분에 '어텐션'하여 보다 정확한 번역을 생성할 수 있도록 합니다.
'인공지능개론' 카테고리의 다른 글
| 이미지&객체탐지관련 알고리즘 조사 (2) | 2023.12.22 |
|---|---|
| AI에 대한 자신의 생각 정리 (2) | 2023.12.22 |
| Fine-tuning (0) | 2023.12.19 |
| 인공지능개론 - 성능지표(F1-score/ mAP/ IoU) (0) | 2023.11.06 |


